
047 网络传输基础:TCP 连接建立与数据序列化

047 网络传输基础:TCP 连接建立与数据序列化
小米里的大麦网络传输基础:TCP 连接建立与数据序列化
1. TCP 协议通信流程
1. 通讯流程总览
下图是基于 TCP 协议的客户端/服务器程序的一般流程:
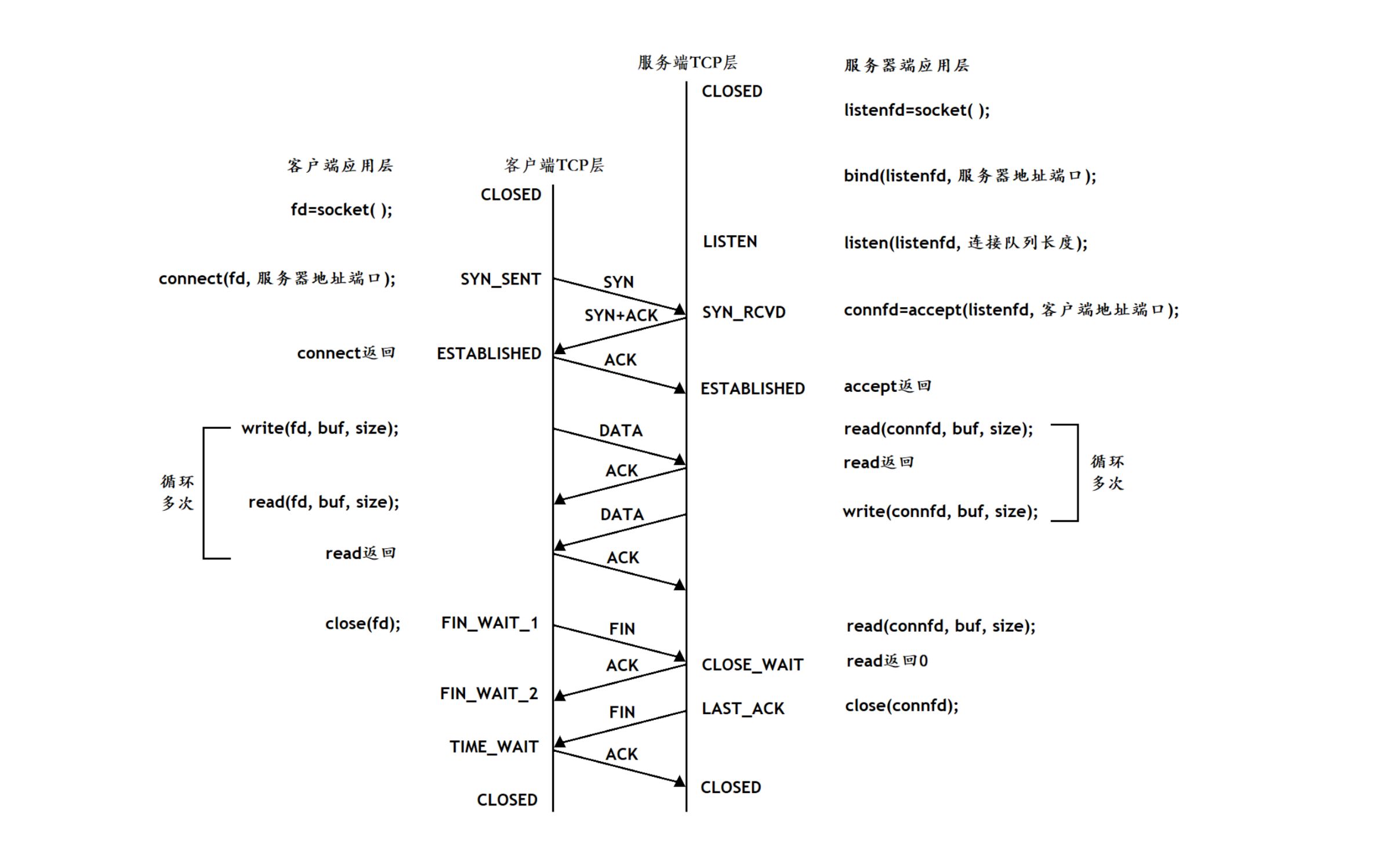
2. TCP 的“三次握手”和“四次挥手”
1. 三次握手——建立连接
目的:确保客户端和服务器都能正常收发数据,建立双向通信连接。
1. 过程描述
第一次握手(SYN)
- 客户端发送一个 SYN 报文:SYN = 1(同步序列号),挑个初始序号 seq = x 给服务器。
- 表示“我想建立连接”,这边的起始序号是 x。
- 客户端进入
SYN_SENT状态。
第二次握手(SYN+ACK)
- 服务器收到 SYN 后,回复一个 SYN+ACK 报文(SYN = 1, ACK = 1, 确认号 ack = x+1,挑个自己的序号 seq = y)。
- 表示“我收到了你的请求,我也准备好了”。
- 服务器进入
SYN_RECEIVED状态。
第三次握手(ACK)
- 客户端收到 SYN+ACK 后,发送一个 ACK 报文(ACK = 1, seq = x+1, 确认号 ack = y+1)。
- 表示“我也确认你的准备就绪”。
- 客户端进入
ESTABLISHED状态。 - 服务器收到 ACK 后,也进入
ESTABLISHED状态。
此时,连接建立完成,双方可以开始传输数据。
2. 为什么需要三次握手?(为什么不能两次?)
举个生活例子(打电话):想象你和朋友打电话:
- 你打电话过去:“喂,听得到吗?”(第一次:SYN)
- 朋友说:“听得到!你听得到我吗?”(第二次:SYN+ACK)
- 你说:“听得到,开始说正事!”(第三次:ACK)
这时候,双方都确认了:
- 我能说话(能发)
- 我能听到(能收)
- 对方也能说话、也能听
如果只有两次握手会怎样?
一个迟到的连接请求(SYN)到达服务器后,服务器会误以为是新请求,立即建立连接并分配资源,但客户端早已放弃,导致服务器白白等待、浪费资源。三次握手通过客户端的最后一次确认(ACK),确保只有真正的有效连接才能建立——如果请求过时,客户端不会回应,连接就不会完成。这就是为什么必须三次,不能两次。
所以:如果只有两次,客户端确认了服务端,但服务端还不确定客户端能否接收消息。三次握手是为了同步初始序列号、避免历史连接干扰、确保双向通信能力。
2. 四次挥手——断开连接
目的:安全、可靠地关闭双向连接。
TCP 是全双工(两边能同时收发)的,断开时需要 分别关闭 发送方向。就像打电话,挂断要双方都说“我说完了”,否则可能有话丢失。因此,关闭连接时,每个方向都需要单独关闭。
简单理解:
- 全双工: 通信双方都能随时收和发数据,互不影响。好比一条双向车道,车辆可以同时从两个方向行驶。
- 非全双工:
- 半双工: 能双向通信,但不能同时,就像对讲机,一方说完另一方才能说。
- 单工: 只能单向传数据,比如收音机接收广播信号,只能收不能发。
1. 过程描述
第一次挥手(FIN)
- 客户端(主动关闭方)发送 FIN 报文(FIN = 1, seq = u)。
- 表示“我说完了,不想发数据了,但还能收”。
- 客户端进入
FIN_WAIT_1状态。
第二次挥手(ACK)
- 服务器收到 FIN 后,发送 ACK 报文(ACK = 1, seq = v, ack = u+1)。
- 表示“收到,你不发就不发吧,但我这边可能还有话要说”。
- 服务器进入
CLOSE_WAIT状态。 - 客户端收到后,进入
FIN_WAIT_2状态。 - 此时,客户端到服务器方向关闭,但服务器还可以继续发送数据。
第三次挥手(FIN)
- 服务器说完了(处理完剩余数据后),发送自己的 FIN 报文(FIN = 1, ACK = 1, seq = w, ack = u+1)。
- 表示“我也发完了,不发数据了,可以关闭了”。
- 服务器进入
LAST_ACK状态。
第四次挥手(ACK)
- 客户端收到服务器的 FIN 后,发送 ACK 报文(ACK = 1, seq = u+1, ack = w+1)。
- 表示:“收到,你也说完了”。
- 进入
TIME_WAIT状态,等待 2MSL 后关闭。 - 服务器收到 ACK 后,进入
CLOSED状态。
此时连接彻底关闭。
2. 为什么需要四次挥手?
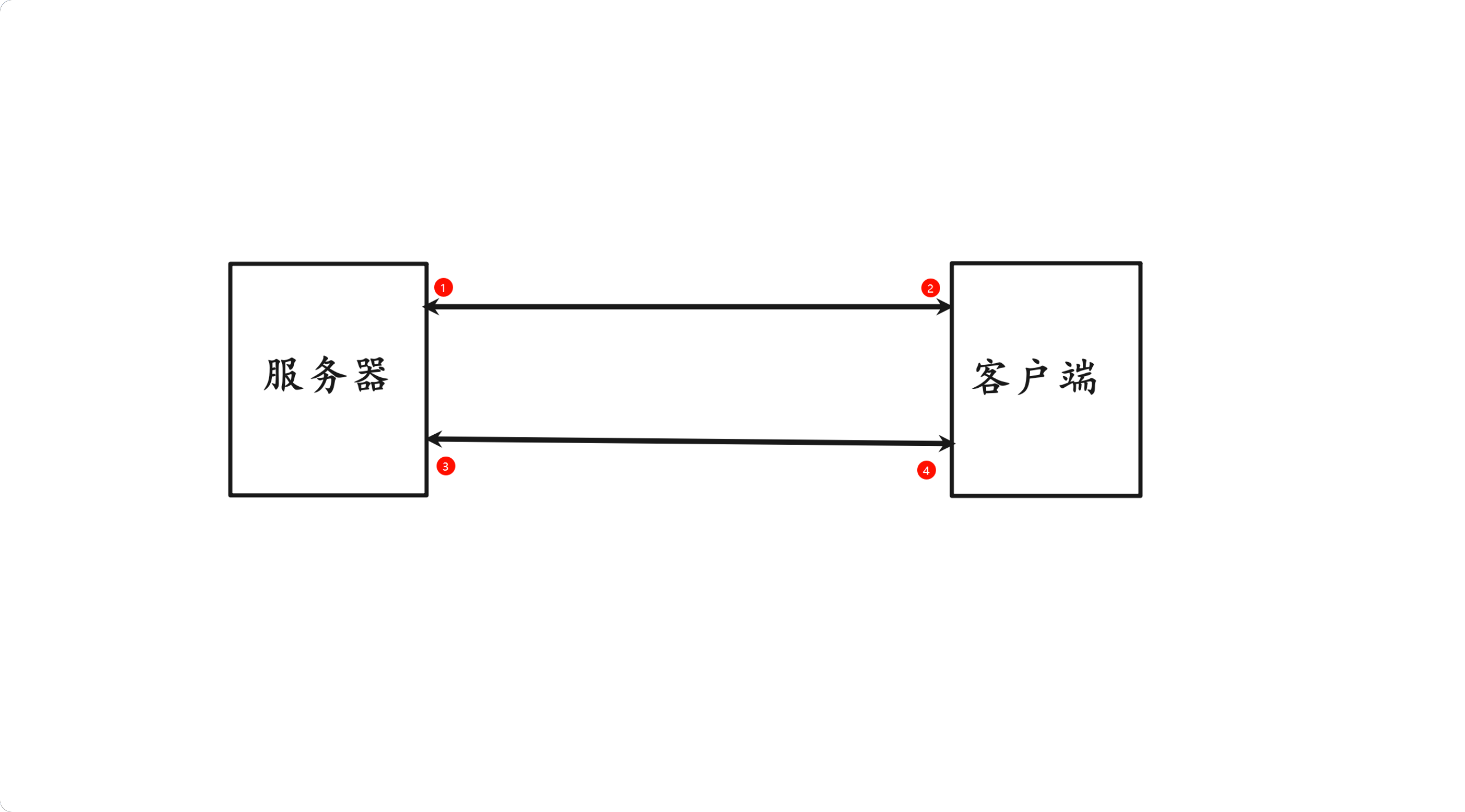
因为 TCP 是 全双工 的,连接的两个方向是独立的。4 个方向要单独处理关闭,得四次挥手来确保数据完整传输。简单理解:就像下面这张图一样,4 个方向独立,每一次挥手关闭一条单向箭头,直到彻底关闭,当然关闭有一定的顺序,只是图中没有体现。
3. 为什么客户端要等待 2MSL?
- 确保最后一个 ACK 能到达服务器: 如果 ACK 丢失,服务器会重发 FIN,客户端必须能重发 ACK。
- 让旧连接的报文在网络中消失: 防止旧连接的延迟报文干扰新连接(MSL 是报文在网络中存活的最长时间)。
所以:四次挥手是为了安全关闭双向连接,保证数据不丢失,连接状态彻底清理。
3. 形象理解
- 三次握手 → 像打电话:
- A:“喂,你能听到吗?”(SYN)
- B:“能听到,你能听到我吗?”(SYN+ACK)
- A:“能听到,开始说吧。”(ACK)
- → 开始通话。
- 四次挥手 → 挂电话:
- A:“我说完了,要挂了。”(FIN)
- B:“我知道了,我还有话说。”(ACK)
- (B 继续说)
- B:“我也说完了,可以挂了。”(FIN)
- A:“收到,拜拜。”(ACK)
- → 挂断。
之前看到一个评论,分享给大家:

2. 序列化和反序列化
1. 反序列化就是“打包”和“解包”?
- 序列化:把内存中的“数据”变成能保存或传输的“字符串或字节流”。类比把东西打包进箱子(变成能传输的格式)。
- 反序列化:把“字符串或字节流”还原成程序能用的“数据”。对方拆箱,取出原物(还原成程序能用的数据)。
想象你要寄一个玻璃花瓶:花瓶 = 程序里的数据(比如一个对象,结构体),直接寄?会碎!所以要:打包 → 塞泡沫 → 装箱(这就是 序列化);对方收到后:拆箱 → 拿出花瓶(这就是 反序列化)。一个简单的例子,直观感受一下:
1 | // 序列化 = 把结构体“拍平”成一串字节 |
2. 在网络传输中,是否一定需要序列化和反序列化?
几乎一定需要, 因为:内存中的数据(对象、结构体、类实例)是 程序内部格式,不能直接通过网络发送。网络只能传输 字节流,比如一串 0 和 1。所以必须先把数据“翻译”成字节流 → 序列化,接收方再“翻译”回来 → 反序列化。
如果只是传一个整数、一个字符串,直接 send()/recv() 就能搞定,甚至用 memcpy 把结构体转成字节流也能传。像这种小 demo、进程间通信,这种“裸字节”就够了。但在绝大多数的情况,要完成复杂的网络通信时,所有跨进程、跨机器的数据传输,都绕不开序列化。
3. 序列化和大小端有关系吗?
有关系,但只在特定格式下才需要关心。
在内存里,一个 int=0x12345678,在 小端机器 上存储是 78 56 34 12,在 大端机器 上存储是 12 34 56 78。如果直接把 int 的内存发过去,接收方解析时字节顺序不同,值就错了。所以序列化要么:
- 明确规定用 网络字节序(大端)(像 TCP/IP 协议族就是这样)。
- 或者用高层格式(比如 JSON、Protobuf),里面数字都用字符串/标准二进制编码,不依赖机器字节序(以后详解)。
结论:序列化的意义之一就是屏蔽大小端差异,保证不同机器都能正确解读。还有一个优点:即使不同系统、语言之间,只要遵循相同序列化协议,也能准确交换数据。
网络传输中,TCP/UDP 虽规定整数需用大端字节序(网络字节序),但这只解决多字节整数的字节顺序问题;而序列化是将复杂数据结构(如结构体、字符串、浮点数等)转换为可传输的字节流的完整过程,包括字段顺序、类型表示、对齐处理等,网络字节序只是序列化中的一个环节。两者不是一回事,网络字节序解决的是“传输层的整数格式统一”,序列化解决的是“应用层数据结构的描述和还原”。
4. 序列化的格式是自定义的,还是有标准?
两者都有,一般强烈建议用标准格式。 标准格式有很多,优点:跨语言、有库、安全、性能好。这部分以后再说。自定义格式不推荐,一般适用于我们的 demo。比如:
1 | name:zhangsan|age:25|city:beijing |
用一些特殊字符/手段进行分割,然后自己再按照特定的格式进行解析。
5. 网络计算器
这部分文件较多,代码较长,感兴趣可移步至 GitHub 观看。
6. 使用 json 进行序列化和反序列化
JSON 和这个 protocol 在进行序列化和反序列化当中非常广泛,通常不需要我们自定义序列化的格式,通常只有在数据结构复杂、高性能的场景下才会使用自定义其格式,比如游戏行业、工业控制领域、对性能要求极高的系统间通信。
jsoncpp 库是一个非常成熟和经典的 C++ JSON 库,在许多 Linux 发行版中都是默认的 JSON 库选择。
1. 安装 JsonCpp(使用 yum)
1. 安装命令
1 | sudo yum install jsoncpp-devel |
2. 验证是否安装成功
1 | ls /usr/include/jsoncpp/json # 检查头文件 |
2. JsonCpp 简单的使用(序列化 & 反序列化)
| 场景 | 代码 |
|---|---|
| 定义 | Json::Value v; |
| 赋值 | v["key"] = value; |
| 数组添加 | v.append(item); |
| 转字符串 | Json::writeString(builder, v) |
| 解析字符串 | parseFromStream(builder, iss, &v, &err) |
| 取字符串 | v["key"].asString() |
| 取整数 | v["key"].asInt() |
| 判断是否存在 | v.isMember("key") |
| 遍历数组 | for (auto& item : array) |
| 遍历对象 | for (auto it = obj.begin(); it != obj.end(); ++it),用 it.name() 取键 |
Json::Value 是核心数据类型,所有 JSON 数据都用 Json::Value 表示,可存储对象、数组、字符串、数字、布尔等。
1 |
|
1 |
|













