
050 传输层 —— UDP

050 传输层 —— UDP
小米里的大麦传输层 —— UDP
1. 再谈端口号
1. 端口号与五元组通信模型
端口号(Port)标识了一个主机上进行通信的不同的应用程序。
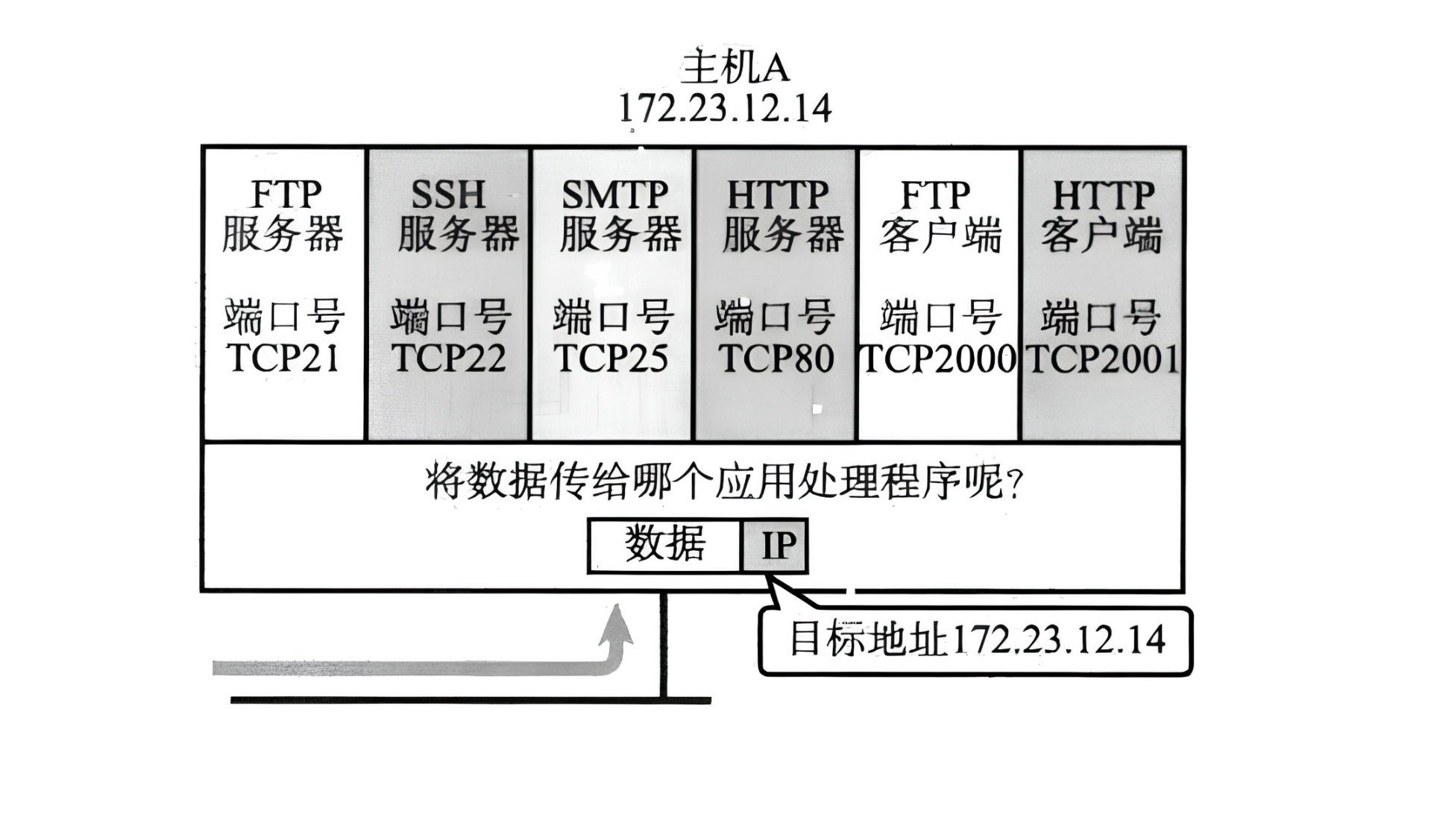
在 TCP/IP 协议中,一个 通信连接 由五元组唯一标识:(源 IP, 源端口, 目的 IP, 目的端口, 协议号)。
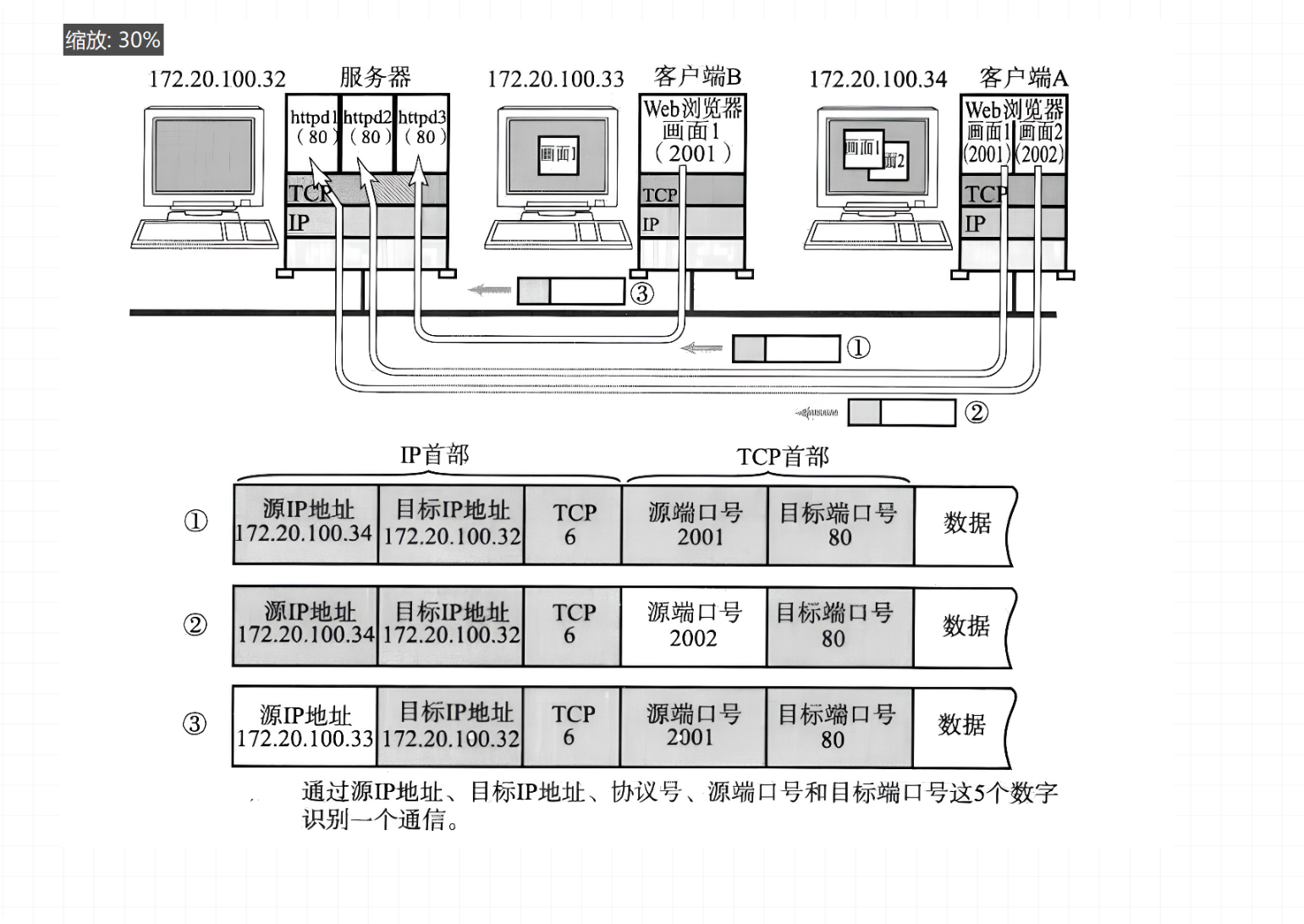
为什么需要五元组?
- 一台主机可以同时与多个远程主机通信。
- 同一个远程主机可以同时提供多个服务(如 HTTP + SSH)。
- 同一个服务可以被多个本地进程(客户端)访问。
- 所以必须用五元组才能 唯一标识一条连接。
查看当前连接:
1 | netstat -n |
2. 端口号范围划分
| 范围 | 名称 | 说明 |
|---|---|---|
| 0 - 1023 | 知名端口 | 系统保留,通常需要 root 权限绑定。如 80(HTTP), 443(HTTPS), 22(SSH) 等。 |
| 1024 - 49151 | 注册端口 | 用户程序或第三方服务可注册使用(如 MySQL 3306, Redis 6379) |
| 49152 - 65535 | 动态/私有端口 | 操作系统自动分配给客户端程序的临时端口 |
注:不同系统对“动态端口”的起始值可能不同(Linux 默认从 32768 开始,可通过
cat /proc/sys/net/ipv4/ip_local_port_range查看)。在我的主机上运行结果是32768 60999,这就表示 Linux 会随机选择 32768 到 60999 之间的端口号给我自己的客户端进程进行分配。
查看知名端口映射:
1 | cat /etc/services |
编辑(不要随意修改!):
1 | sudo vim /etc/services # cat 不好查看这样的长内容,用 vim 观看体验会好一点,但不要进行修改!! |
我们自定义程序端口建议避开 0-1023,最好使用 1024 以上未被占用的端口,从而避开这些知名端口号。
3. 两个关键问题
1. 一个进程是否可以 bind 多个端口号?
可以! 一个进程可以创建多个 socket,分别 bind 到不同的端口。例如:Nginx 可以监听 80 和 443;一个程序可以同时提供 HTTP 和管理 API。
1 | // 伪代码示意 |
2. 一个端口号是否可以被多个进程 bind?
我们一般接触到的情况都不行!
- 操作系统规定:同一时间,一个端口(如
80)只能有一个进程处于 LISTENING 状态。否则无法区分到底该把流量交给哪个进程。 - 如果强行 bind,会报错
Address already in use。
但也存在例外情况(了解):
- 使用
SO_REUSEADDR或SO_REUSEPORT选项时,多个进程/线程可以监听同一个端口,但一般用于 负载均衡(如 Nginx 多 worker)。 - 这种情况下,内核会把新连接分配给其中一个进程。
4. 命令详解:netstat, pidof
1. netstat —— 查看网络连接、路由、接口等
常用选项(netstat -tulnp):
- -t:仅显示 TCP 相关选项。
- -u:仅显示 UDP 相关选项。
- -l:仅列出有在 Listening(监听中的)服务状态。
- -n:拒绝显示别名,能显示数字的全部转化成数字。
- -p:显示建立相关链接的程序名、进程 PID(需要 root)。
- -a(all):显示所有选项默认不显示 LISTEN 相关。
示例:
1 | netstat -n # 用数字显示,不反查域名/服务名 |
在较新 Linux 系统中,
ss(socket statistics)开始逐渐替代netstat。
2. pidof —— 通过程序名获取进程 PID
语法: pidof [程序名]。
示例:
1 | pidof httpd # 查 httpd 的进程号 |
常见用法:
1 | pidof httpd |
3. 命令行参数转化问题
命令行示例:
1 | ps ajx | head -1 && ps ajx | grep httpd | awk '{print $2}' | xargs kill -9 |
命令行本意:
ps ajx | head -1→ 打印ps ajx的表头(列名),方便对照列号&&→ 表示前面命令成功(退出码 0)才执行后面的命令,这里head -1几乎总是成功,所以后面一定会执行。ps ajx | grep httpd→ 找出所有含有httpd的进程。awk '{print $2}'→ 取第 2 列(以为这一列就是 PID)。xargs kill -9→ 把 PID 传给kill -9,强制结束进程。
目的就是:先看看进程表头 → 再杀掉所有 httpd(这个 d 就表示是守护进程 ) 进程。
为什么有问题?
本来只想杀掉 httpd,结果不小心连 grep httpd 这个查找命令自己也一起杀了 —— 虽然它“死得快”,但逻辑是错的,还可能误杀别的!
grep httpd会把自己也列出来,把自己运行的查找命令也一起杀掉,虽然grep命令通常 0.1 秒就结束了,杀它没实际影响,但 逻辑错误!不专业!- 如果系统里没有 httpd,命令会报错!
怎么解决?
- 最简单 —— 直接用
pkill,pkill -9 httpd(进程名,非ID)→ 系统自带的“精准杀手”,专门干这个活,不会杀自己,找不到也不报错。 - 用
pidof,pidof httpd | xargs kill -9→pidof只找“程序名叫 httpd”的进程,不会找 grep,很干净。 - 非要自己写,加个“防自杀”技巧:
ps ajx | grep [h]ttpd | awk '{print $2}' | xargs kill -9→[h]ttpd和httpd效果一样,但命令名是grep [h]ttpd,不会匹配自己(也叫“grep 防自爆写法”)。
4. 关于 iostat
iostat:I/O statistics → 磁盘、CPU 使用情况。netstat:network statistics → 网络、端口情况。
它和网络/端口无关,它只是一个 查看磁盘 I/O 统计 的工具,用于收集 CPU 使用情况 和 块设备(磁盘/分区)I/O 性能数据,帮助我们了解系统的 I/O 瓶颈。安装命令:sudo yum install sysstat。
1 | iostat # 显示 CPU 使用率 + 每个设备的 I/O 概况 |
指标讲解(磁盘部分):
| 字段 | 含义 |
|---|---|
r/s | 每秒读请求数(读 IOPS) |
w/s | 每秒写请求数(写 IOPS) |
rkB/s | 每秒读的 KB 数(读吞吐量) |
wkB/s | 每秒写的 KB 数(写吞吐量) |
await | 平均每个 I/O 请求的等待时间(毫秒),越小越好 |
svctm | 服务一个 I/O 请求的时间(毫秒) |
%util | 磁盘繁忙程度(100% = 跑满了) |
直观判断:
%util接近 100%,磁盘被打爆了。await很大,说明 I/O 延迟严重。- IOPS (
r/s+w/s) 很高,但%util没满 → 磁盘性能还行。
CPU 部分指标:
| 字段 | 含义 |
|---|---|
%user | 用户态 CPU 占比(应用程序消耗) |
%system | 内核态 CPU 占比(系统调用消耗) |
%iowait | 等待 I/O 的时间占比(越高越说明磁盘慢) |
%idle | 空闲时间 |
直观判断:
%iowait很高,说明 CPU 大部分时间都在等磁盘。%user高 → 应用很吃 CPU。%idle高 → 系统很闲。
2. UDP 协议
1. UDP 协议段格式
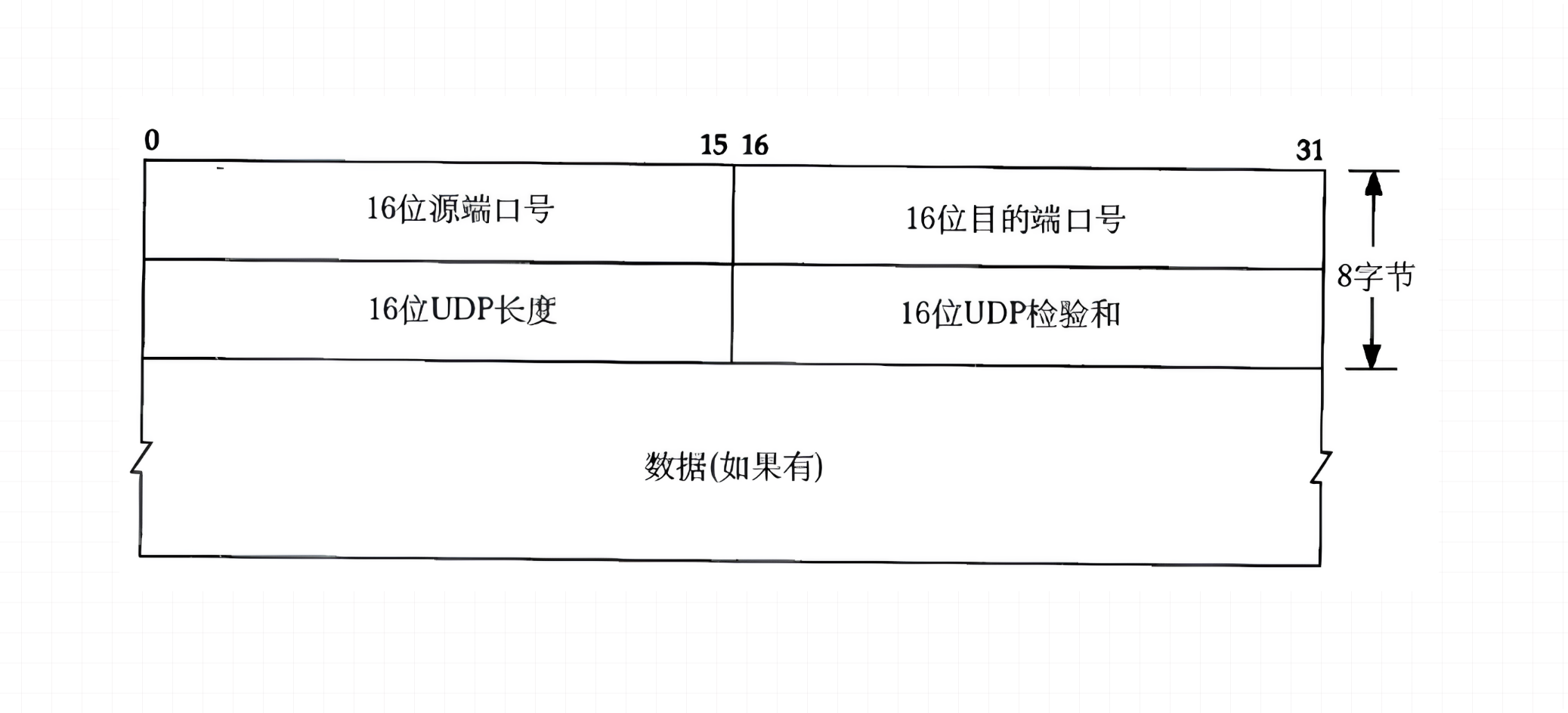
16 位指 16 个二进制位,即 0 或 1,8 位等于 1 字节,16 位就是 2 字节。
UTF-16 不常用,UTF-8 更常用。它是一种变长字符编码,简单且直观的来说就是在 UTF-8 中,一个英文字符就占 1 字节,一个中文字符就占 3 字节,少数生僻字等占 4 字节。
UDP 报头总是 8 字节(64 bit),分成四个 16 位字段,按顺序排放:
- 源端口号(16 位)
- 目的端口号(16 位)
- UDP 长度(16 位) —— 包括整个 UDP 数据报(头部 + 数据)的长度。
- 校验和(16 位) —— 校验 UDP 报文在传输中是否出错(发送方用特定算法,将伪首部、UDP 首部和数据部分计算出校验和存于报头。接收方同样计算并对比,若不一致 通常丢弃数据包,但也可交给上层并附错误报告 )。
紧接着就是 数据(有效载荷),长度由 “UDP 长度”字段减去 8(报头大小)得出。
在 Linux 下用 C 语言实现时,UDP 报头是一个自定义结构体。具体表现为(cat /usr/include/netinet/udp.h):
1 | struct udphdr |
2. UDP 报文是“矩形”的还是线性的?
图中“矩形”矩形结构只是一种 逻辑结构图/一种可视化方式,用来帮助理解字段布局、说明各个字段的位置和大小。实际网络上传输时(物理传输层面),报文是 一维线性的比特流(字节流)。换句话说,发送出去的数据包在网线上就是一串 0 和 1,不是二维矩形。
实际在网络中,UDP 数据报是一个连续的字节序列,按顺序排列如下:[源端口][目的端口][长度][检验和][数据...],举个例子:假设一个 UDP 数据报有 100 字节数据,则总长度为 8(头部)+ 100 = 108 字节。这些字节会依次封装进 IP 包中,通过网络传输。
在协议层面 面向数据报,UDP 以数据报为单位处理数据,有独立边界;在物理传输层面,为适配网络介质,数据报要转化为 比特流(字节流)传输,一个是逻辑处理方式,一个是实际传输形式 。
3. 报头和有效载荷是如何分离的?
关键点是 UDP 长度字段,通过它确定报头后 8 字节的边界,从而分离出有效载荷。接收方先看前 8 字节是报头,再找出 “UDP 长度” 这个信息,从第 9 字节开始,用 “UDP 长度” 减 8 得到的字节数就是有效载荷。或者简单说,先确定 8 字节报头,IP 层把数据给 UDP 后,剩下的就是有效载荷。
4. 有效载荷如何交付给上层?
当 UDP 收到数据报后:
- 根据 目的端口号 查找对应的应用程序(如 DNS、NTP、游戏等)。
- 将有效载荷交给该应用程序处理。
- 应用程序通常通过 socket 接口接收数据(例如
recvfrom())。
比如在线视频播放时,视频流数据通过 UDP 传输,目的端口号对应视频播放应用程序,UDP 把有效载荷交给它,就能播放视频了。
UDP 不保证送达、不排序、不重传,所以交付是“尽力而为”。
5. UDP 的应用场景有哪些?
UDP 的特点:简单、无连接、不保证可靠传输、面向数据报,但开销小、延迟低。 适用于:
- 实时通信:语音通话(VoIP)、视频会议、在线游戏(延迟比可靠性更重要)。
- 简单查询服务:DNS(域名解析)、SNMP(网络管理)、DHCP(动态主机配置)。
- 广播、多播:如局域网内的服务发现。
6. 如果 UDP 数据包太大怎么办?
分片就像是把大包裹拆成几个小包裹来寄。UDP 数据包太大时,IP 层会把它拆分。丢包就是这些小包裹在运输(网络传输)过程中丢失了。一旦有小包裹丢了,因为 UDP 不会重新发送,整个数据就用不了。
UDP 没分段机制,数据包大小受 MTU(最大传输单元)限制。 比如 IPv4 的 MTU 一般 1500 字节,减去 IP 头部(20 字节)和 UDP 头部(8 字节)后就是数据最大长度(最大 UDP 载荷约为 1472 字节)。超了就由 IP 层分片,像把大文件拆成小文件。但分片可能丢包,现代设备还可能拒绝分片。应对办法有控制数据大小、用路径 MTU 发现或改用 TCP 协议等。
7. UDP 的缓冲区
UDP 无真正发送缓冲区,sendto 调用后数据直给内核再传网络层。它有接收缓冲区,但不能保证接收顺序与发送一致,若缓冲区满,新到的 UDP 数据会被丢弃。UDP 的 socket 可同时读写,具备全双工特性 。













